
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 데이터 분석
- 코딩테스트 연습
- 머신러닝
- 웹모의해킹
- vagrant
- 데이터3법
- 마이데이터
- 자료형
- XSS 취약점
- 데이터분석
- 알고리즘
- 코딩테스트
- AWS
- 코테
- 시저암호
- 파이썬 문법
- 컴퓨터 구조
- 클라우드
- 개인정보보호법
- 웹 모의해킹
- 도커
- 회귀분석
- 백준
- docker
- AI
- 함수
- 개인정보보호
- 파이썬
- 프로그래머스
- 정보보안
Archives
- Today
- Total
찬란하게
[개인정보] k-익명성 l-다양성 t-근접성 본문
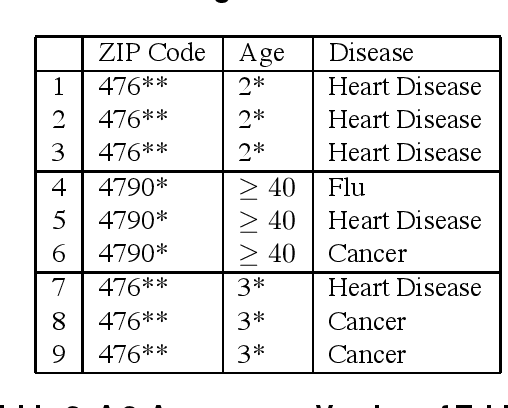
k-익명성
공개 데이터에 대한 연결 공격을 방어하기 위해 제안된 프라이버시 보호 모델이다.
2002년 L.Sweeney가 제안한 모델
K-anonymity
특정 개인을 식별할 수 없도록
전체 데이터셋에 동일 값 레코드 (=동치류) k개 이상 존재하도록 하는 비식별 모델
가장 작은 k값이 전체 데이터의 k-익명성을 대표함
k값이 작아질수록 재식별 가능성이 높아짐
- 동치류(equlvalence classes) : 준식별자 속성값이 동일한 레코드의 모임
동치류 = 준식별자 속성값이 동일한 레코드의 수 : k값
취약점
- 동질성 공격 (homogeneity attack), 배경지식 공격 : 민감한 속성이 다양하지 않아 데이터의 추정 가능
l-다양성
다른 민감한 정보를 가진 레코드의 수를 l이라 하고,
최소값을 l값으로 지정한다.
l-diversity; ℓ-diversity
주어진 데이터 집합에서 함께 비식별되는 레코드들은 (동질 집합에서)
적어도 ℓ개의 서로 다른 민감한 정보를 가져야 하는 성질
k-익명성에 대한 두 가지 공격, 즉 동질성 공격 및 배경지식에 의한 공격을 방어하기 위한 모델
동치류안에서 민감한 속성값을 가지는 레코드 수 : l값

취약점
- 쏠림 공격 : 동치류간 비율이 다르게 나옴
- 유사성 공격 : 의미유사성 고려하지 않음
t-근접성
t-closeness
동질 집합에서 특정 정보의 분포와 전체 데이터 집합에서
정보의 분포가 t이하의 차이를 보이도록 하는 성질
l-다양성의 취약점(쏠림 공격, 유사성 공격)을 보완하기 위해 모델
각 동질 집합에서 ‘특정 정보의 분포’가 전체 데이터집합의 분포와 비교하여 너무 특이하지 않도록 함
전체 데이터 집합과 동일하면 t = 0
t값이 작을수록 비식별화 수준이 높음
'정보보안 > 개인정보보호' 카테고리의 다른 글
| [개인정보] 개인정보보호 사이트 3대장 (0) | 2021.05.24 |
|---|---|
| [개인정보] 가명처리 절차 (0) | 2021.05.21 |
| [개인정보][용어] 비식별화 (0) | 2021.05.21 |
| [개인정보] EU GDPR : General Data Protection Regulation (0) | 2021.05.21 |
| [개인정보] 데이터 3법 개정 (0) | 2021.05.20 |
'정보보안/개인정보보호' Related Articles
more


